


※本記事は継続的に最新情報へアップデートしています。
RAGプラットフォーム比較で本当に見るべきポイントは、「どちらが高性能か」ではない。自社がどこまで作り、どこから先をマネージドサービスに任せるかである。
Vertex AI RAG Engine、Vertex AI Search、Agent Search、LlamaIndex、LlamaCloud、LlamaParseは、同じRAG領域に見えても役割が異なる。選び方を誤ると、PoCは速くても本番運用で詰まる。
本記事では、AI駆動開発でRAGを構築するエンジニアに向けて、実装負荷、デバッグ可能性、検索品質改善、権限・監査、運用責任の観点から、現実的な選び方を整理する。
✅ 先に結論
RAG基盤の選定は、Vertex AIとLlamaIndexの二択ではありません。AI駆動開発でどこまで自動化し、どこから先を人間が設計責任として持つかを決める作業です。
- ポイント1:Vertex AI / Agent Searchは、検索基盤やインフラ運用の負荷を下げやすい一方、IAM、データ接続、サービス制約、ログ設計の理解は残ります。
- ポイント2:LlamaIndexは、Retriever、Reranker、ワークフロー、評価を細かく制御しやすい一方、設計・監視・障害対応の責任は自社側に残りやすくなります。
- ポイント3:LlamaCloud / LlamaParseは、複雑なPDFや帳票処理の負荷を下げますが、抽出品質の評価と業務文書ごとの検証は必要です。
- ポイント4:AI駆動開発でRAG構築は速くなります。ただし、評価基準、権限、監査、責任境界までAIに丸投げすることはできません。

何が変わったのか

RAG構築は、ライブラリ選定の時代から、プラットフォーム選定と運用境界設計の時代へ移っている。
従業員3,000人規模のBtoB企業が、社内問い合わせ対応のためにRAGを導入しようとしていました。PoCは3週間で完成し、デモは好評でした。「これはいける」と全員が思ったのです。
ところが本番化の話になった瞬間、四方から声が上がります。現場のエンジニアは「LlamaIndexで柔軟に作りたい」、情報システム部門は「Google Cloudでマネージドに運用したい」、経営層は「半年後には全社展開したい」、法務部門は「権限管理と監査ログは必須」と条件を出します。
このとき、誰も間違っていません。間違っていたのは、問いの立て方でした。
問いは「Vertex AIとLlamaIndexのどちらが優れているか」ではありません。正しい問いは、自社はRAGのどこを自分たちで持ち、どこをプラットフォームに任せるべきかです。
RAGは、単に文書をベクトル化して検索する仕組みではありません。文書の取り込み、前処理、チャンキング、Embedding、インデックス作成、検索、再ランキング、生成、評価、権限制御、ログ、継続改善まで含むシステムです。だからこそ、PoCの段階では数行のコードで動いても、本番運用では別の課題が現れます。
2026年現在、RAG構築の選択肢は大きく広がっています。Google CloudはVertex AI RAG Engine、Vertex AI Searchによるグラウンディング、Agent Search、Gemini Enterprise Agent Platformを通じて、マネージドなRAG・エージェント基盤を整備しています。一方、LlamaIndexはOSSフレームワークとして柔軟なRAG設計を支え、LlamaCloud / LlamaParseによって文書解析・抽出・インデックス作成・検索までをマネージド化する選択肢も提供しています。
つまり、RAGのプラットフォーム選定は、クラウドかOSSかの二択ではありません。「速く始める」「深く作る」「安全に運用する」のバランスを決める経営判断になっています。
RAGクラスターにおける本記事の位置づけ
| 記事領域 | 扱う問い | 本記事との関係 |
|---|---|---|
| RAG完全ガイド | RAGとは何か、どの工程で構成されるか | 全体像の正典ハブ |
| RAGデータパイプライン | 文書をどう取り込み、検索できる知識に変えるか | プラットフォーム選定前の入口設計 |
| RAG Embedding | 文書をどうベクトル化するか | 検索基盤の前提技術 |
| ベクトルDB | ベクトルとメタデータをどこに格納するか | Vertex AI Vector Searchや外部DB選定と接続 |
| Agentic RAG | RAGをどう自律化・評価駆動化するか | LlamaIndexやAgent Platformとの接続先 |
| 本記事 | どの基盤でRAGを構築・運用するか | プラットフォーム選定ガイド |
なぜ今重要なのか

RAGはPoCの実装技術から、運用・監査・権限制御を含む企業基盤へ進化している。誰が、何を、どの権限で更新しているかを答えられる設計が必要である。
RAGの初期段階では、開発者がライブラリを使って小さな検索QAを作ることが中心でした。社内文書を読み込み、チャンク化し、Embeddingし、ベクトルDBに入れ、LLMに回答させる。PoCとしては、それで十分に見えます。
しかし本番導入では、別の問いが立ち上がります。誰が文書を更新するのか。古い版をどう除外するのか。部署ごとの閲覧権限をどう守るのか。検索ログをどう評価するのか。失敗回答をどう再学習・再設定につなげるのか。これらは、単なるライブラリ選定だけでは解けません。
Google CloudのRAG Engineは、RAG corpusの作成、ファイル取り込み、チャンク設定、Embedding、検索、Geminiとの連携を含むマネージドなRAG構築手段として整備されています。2026年5月時点では、Serverlessモードもプレビュー提供されており、インフラ構成のプロビジョニングや管理負荷をさらに下げる選択肢になっています。
また、Agent Searchは、コネクタやUIを通じて、ETL・OCR・チャンキング・Embedding・Indexing・検索・要約といったRAG向け処理の多くを設定ベースで扱える検索基盤として位置づけられています。
一方、LlamaIndexは、RAGやLLMアプリケーションを構築するためのオープンソースフレームワークとして出発しました。2026年現在は、LlamaParseやLlamaCloudを含む文書AI基盤と一体で見ることで、RAGだけでなく文書エージェントやOCRワークフローまで視野に入るプラットフォーム群として捉えられます。
つまり、RAGの選定基準は「コードが短いか」ではなくなりました。本番で継続的に運用できるか、評価できるか、守れるかが重要になっています。
RAG基盤選定の3つの型
| 型 | 考え方 | 代表例 | 向いている組織 |
|---|---|---|---|
| 買う | RAGの多くをマネージドサービスに任せる | Vertex AI RAG Engine、Vertex AI Search、Agent Search | Google Cloud中心、短期導入、運用人員が限られる企業 |
| 作る | RAGパイプラインを自社で細かく設計する | LlamaIndex、LangChain、独自Vector DB構成 | 高度な検索要件、研究開発、特殊ドメインを扱う組織 |
| 組み合わせる | 文書処理や検索の一部をサービス化し、制御したい部分だけ作る | Vertex AI × LlamaIndex、LlamaCloud × 自社アプリ | 本番品質と柔軟性を両立したい企業 |
Vertex AI / Agent Platformで作るRAG
Vertex AI系のRAG基盤は、検索基盤やインフラ運用の負荷を下げやすい。ただし、IAM、データ接続、サービス制約、ログ、評価設計の理解は依然として必要である。
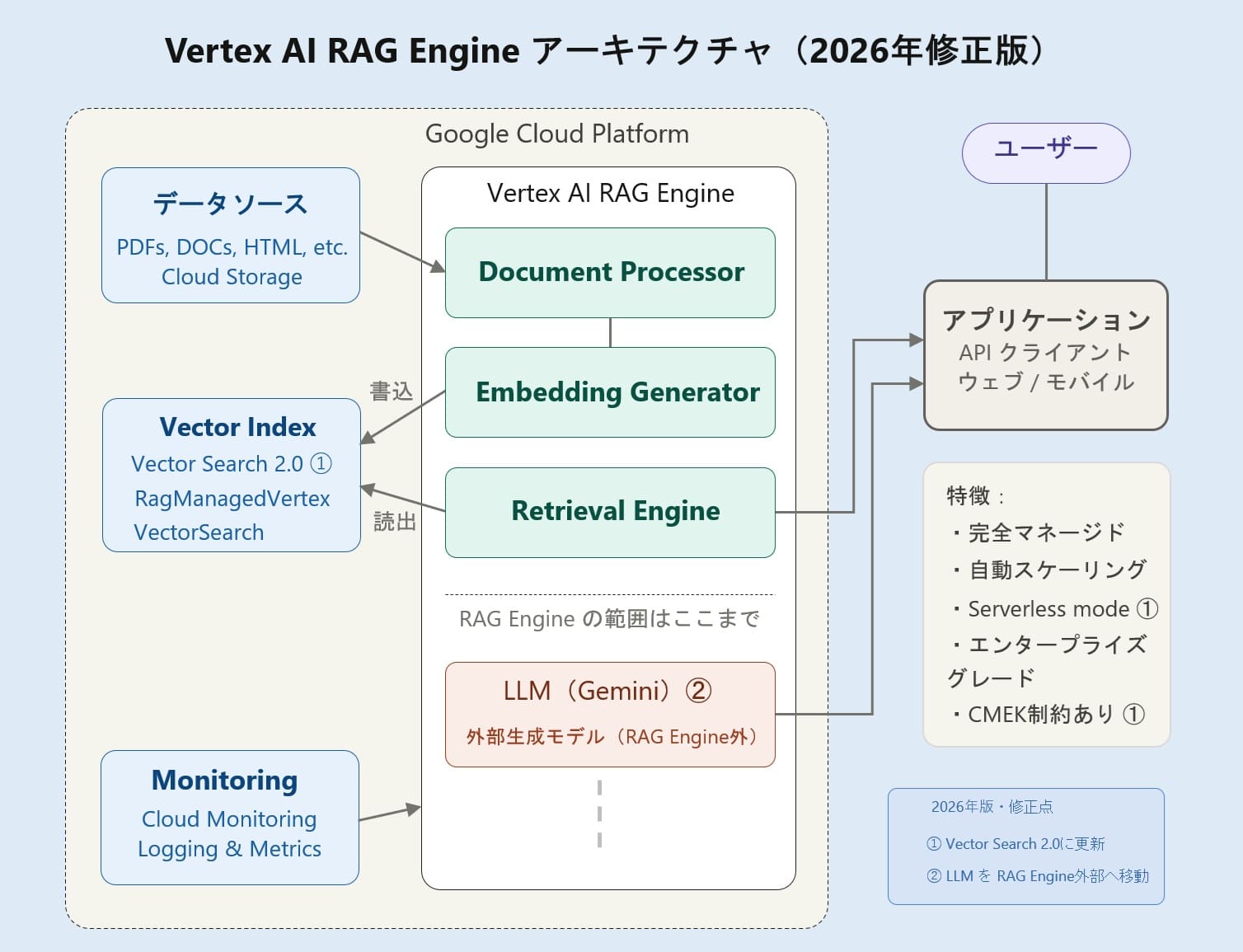
Vertex AI RAG Engineは、Google Cloudが提供するマネージドなRAG構築基盤です。RAG corpusを作成し、ファイルを取り込み、チャンク化し、Embeddingし、検索結果をGeminiなどのモデルに渡す構成を取りやすくします。Google Cloud公式クイックスタートでも、from vertexai import rag を用いたRAG corpus作成、ファイル取り込み、検索、Geminiとの連携が示されています。
2026年5月時点では、Vertex AI RAG EngineのServerlessモードもプレビュー提供されています。インフラ構成のプロビジョニングや管理を抑え、マネージドにRAGデータベースを扱える点は魅力です。Serverlessモードでは、従来のRagManagedDbではなく、デフォルトのベクトルDBとしてRagManagedVertexVectorSearchが使われます。
これはGemini Enterprise Agent Platform Vector Search 2.0を基盤とするフルマネージドなベクトル検索基盤です。ただし、プレビュー機能としての制約や対応リージョン、CMEK非対応などの制限は、必ず最新ドキュメントで確認する必要があります。
また、Vertex AI Searchによるグラウンディングでは、モデルをウェブサイトのデータやドキュメントセットに接続し、RAGとして利用できます。Agent Searchは、検索エンジンや生成AIアプリケーションを企業データにグラウンディングする用途を想定し、ETL・OCR・チャンキング・Embedding・Indexing・検索・要約などを設定ベースで簡素化する基盤として説明されています。
つまり、Google Cloud系の選択肢は、「部品を全部自分で組む」というより、RAGに必要な面倒な土台をGoogle Cloudに寄せる設計です。ただし、エンジニアの仕事がなくなるわけではありません。むしろ、どのログを見て、どの制約を受け入れ、どこをアプリ側で補うかを設計する力が重要になります。
Vertex AI系が強い場面
| 判断軸 | 向いている状況 | 理由 |
|---|---|---|
| クラウド基盤 | Google Cloudをすでに利用している | IAM、Cloud Storage、監査、ネットワーク、Gemini連携を統合しやすい |
| 導入スピード | 短期間でRAGを試し、本番化したい | RAG corpus、検索、Gemini連携などをマネージドに扱いやすい |
| 運用負荷 | 検索基盤やインフラ管理に専任を置きにくい | サーバー、スケーリング、基盤運用をクラウド側に寄せられる |
| セキュリティ | IAM、監査、ネットワーク制御を重視する | Google Cloudのセキュリティ・アクセス制御と組み合わせやすい |
| 生成AI連携 | Geminiを中心にアプリケーションを構築する | RAGをGeminiのツールとして利用する構成を取りやすい |
Vertex AI系で注意すべきこと
Vertex AI系は、RAGの立ち上げを大きく簡単にします。ただし、すべての要件に万能ではありません。検索ロジック、チャンク戦略、外部Vector DB、独自の再ランキング、オンプレミス要件、マルチクラウド要件が強い場合は、マネージドサービスの枠内でどこまで制御できるかを事前に確認する必要があります。具体的には、「接続できるデータソースの種類」「選べるEmbedding/Vector Searchの範囲」「オンプレ/他クラウドとの接続パターン」を事前に洗い出しておくと安全です。
また、Vertex AI RAG Engine、Vertex AI Search、Agent Search、Gemini Enterprise Agent Platformは役割が重なって見えるため、プロジェクト開始時に「何をRAG Engineで担い、何をSearchで担い、何をアプリ側で担うか」を整理することが重要です。
Vertex AI系のRAGは、「自社で検索エンジンを一から作る」のではなく、「Google Cloud上のRAG基盤を使って、業務アプリに近いところへ早く進む」選択です。スピードと運用性が魅力ですが、細部をどこまで自分で触れるかは、事前に見極める必要があります。
LlamaIndex / LlamaCloudで作るRAG

LlamaIndex系のRAG基盤は、Retriever、Reranker、Workflow、評価を細かく制御しやすい。一方で、本番運用と障害時の切り分け責任は自社側に残りやすい。
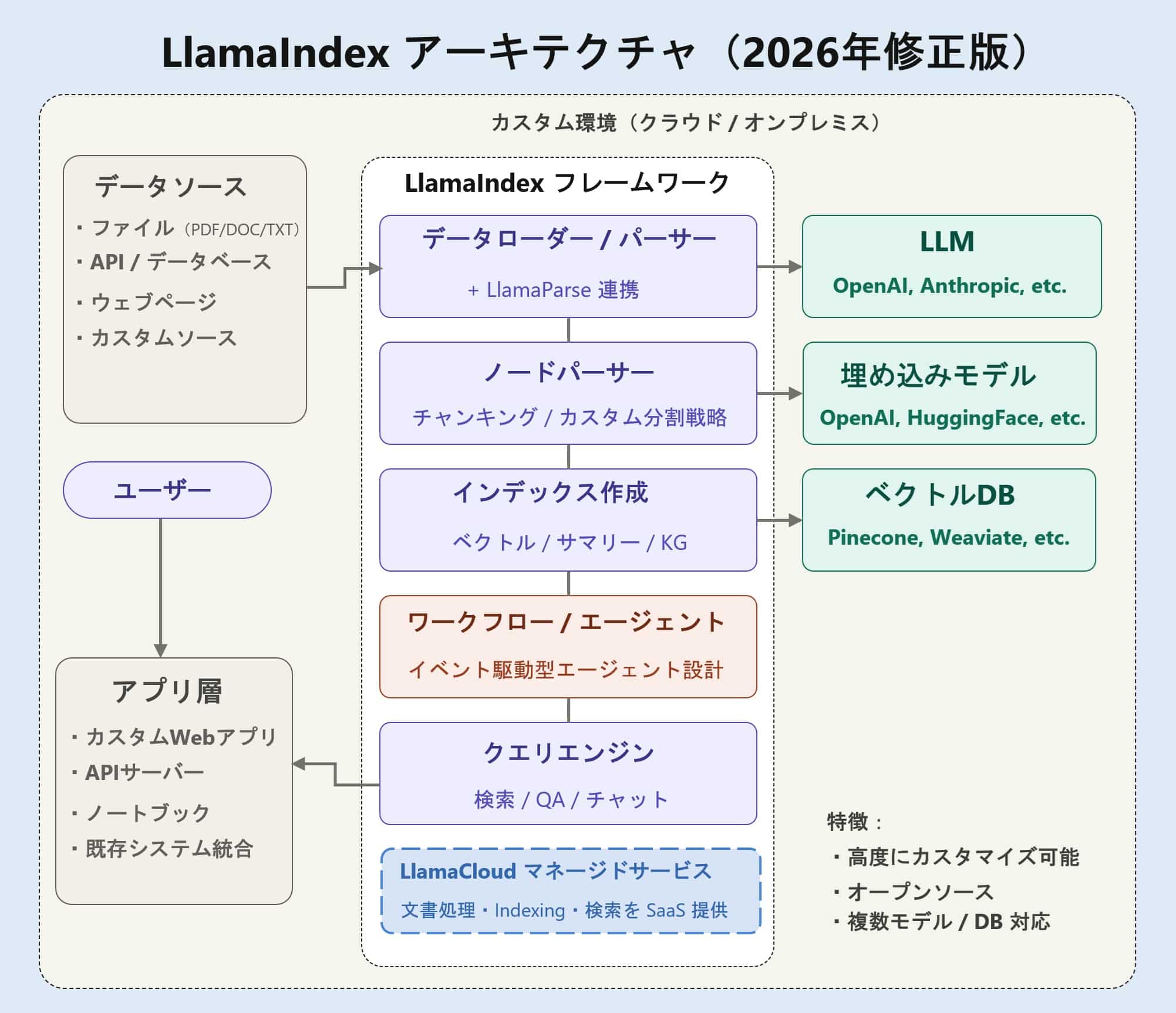
LlamaIndexは、RAGやLLMアプリケーションを構築するためのオープンソースフレームワークとして出発しました。2026年現在は、LlamaParseやLlamaCloudを含む文書AI基盤と一体で見ることで、RAGだけでなく文書エージェントやOCRワークフローまで視野に入るプラットフォーム群として捉えられます。
従来のRAGでは、LlamaIndexは「ライブラリ」として捉えられがちでした。しかし2026年版では、LlamaCloudやLlamaParseも含めて見る必要があります。LlamaCloudは、文書解析、抽出、インデックス作成、検索をマネージドに扱うサービスとして説明されており、LlamaParseは複雑な文書をRAGに使いやすいデータへ変換する文書処理基盤として位置づけられています。
さらに、2025年末に発表されたLlamaParse v2では、設定の簡素化、安定版管理、性能改善、価格面の改善が示されています。Fast、Cost Effective、Agentic、Agentic Plusといった複数のティアから用途に応じて選べるため、2026年時点では、新規プロジェクトでもコストと精度のバランスを取りながら導入しやすい選択肢になっています。
つまり、LlamaIndex系は単なるOSSライブラリではありません。柔軟なRAG設計のためのOSSと、文書処理・Indexingを支えるマネージド基盤の組み合わせとして見るのが自然です。ただし、自由度が高いほど、「なぜこの文書が検索されたのか」「なぜ回答が変わったのか」を自社で追える設計が求められます。
LlamaIndex系が強い場面
| 判断軸 | 向いている状況 | 理由 |
|---|---|---|
| 柔軟性 | 検索、再ランキング、チャンク戦略を細かく制御したい | RAGの各工程を自社要件に合わせて設計しやすい |
| LLM選択 | OpenAI、Anthropic、Google、OSSモデルを使い分けたい | 複数モデル・複数Embedding・複数Vector DBとの接続を設計しやすい |
| 文書処理 | PDF、表、帳票、契約書など複雑な文書が多い | LlamaParseやLlamaCloudを文書処理基盤として活用しやすい |
| 実験速度 | 検索手法や評価方法を頻繁に変えたい | OSSフレームワークとして構成を変えやすい |
| マルチクラウド | 特定クラウドに強くロックインしたくない | クラウド、オンプレミス、ローカル、外部Vector DBと組み合わせやすい |
LlamaParse / LlamaCloudをどう見るべきか
LlamaParseは、複雑なレイアウト、表、グラフ、画像、手書きなどを含む文書を、AIアプリケーションで扱いやすい形に変換する文書解析基盤として紹介されています。LlamaParse Platformの公式ドキュメントでは、Parse、Extract、Classify、Split、Sheets、Indexといった文書AI向け機能が整理されています。RAGやエージェントの前段で、複雑な文書をAIが扱いやすいデータへ変換する基盤として見るのが自然です。
これは、前回整理した RAGデータパイプライン の文脈と直結します。複雑なPDFや帳票が多い企業では、RAGの失敗原因がLLMではなく、文書抽出・表構造・メタデータにあることが少なくありません。その場合、LlamaParse / LlamaCloudは、RAG本体の前段を強化する選択肢になります。
LlamaIndexは「RAGを自分たちで設計するための道具箱」です。LlamaCloud / LlamaParseは、その中でも面倒になりがちな文書解析やIndexingをサービス化する選択肢です。自由度は高い一方で、設計責任も自社側に残ります。
Vertex AIとLlamaIndexをどう比較するか

比較すべきなのは機能数ではなく、自社が持つべき制御範囲と運用責任の範囲である。
ここで、よくある比較の落とし穴があります。それは、Vertex AIとLlamaIndexを「どちらが高性能か」という単純な競争にしてしまうことです。
実際には、両者は同じレイヤーにいるわけではありません。Vertex AI RAG EngineやAgent Searchは、Google Cloud上でRAGをマネージドに構築・運用しやすくするプラットフォームです。一方、LlamaIndexは、RAGパイプラインを柔軟に組むための開発フレームワークであり、LlamaCloud / LlamaParseを使うと文書処理やIndexingをマネージド化できます。
したがって、比較の軸は「勝ち負け」ではなく、どの責任をクラウドに渡し、どの責任を自社に残すかです。
| 項目 | Vertex AI RAG Engine | Vertex AI Search / Agent Search | LlamaIndex | LlamaCloud / LlamaParse |
|---|---|---|---|---|
| 主な役割 | Google Cloud上の構成可能なRAG基盤 | 企業データ検索・グラウンディング・検索体験 | 柔軟なRAGアプリ開発フレームワーク | 文書解析・抽出・Indexingのマネージド基盤 |
| 導入スピード | 速い。Serverlessモードによりさらに簡素化できる可能性がある | 非常に速い | 設計次第 | 文書処理部分は速い |
| 柔軟性 | 中〜高 | 中 | 非常に高い | 文書処理・Indexingに強い |
| 運用負荷 | 低め | 低め | 高め | 中程度 |
| 向く用途 | Google Cloud上のRAG本番化 | 社内検索、FAQ、ナレッジ検索、RAG検索エンジン | 高度な検索設計、Agentic RAG、実験的RAG | 複雑なPDF、帳票、表、文書AIパイプライン |
| 注意点 | Google Cloud前提が強く、プレビュー機能には制約確認が必要 | 細かな制御はサービス仕様に依存 | 設計・運用責任が自社側に残る | 商用サービスとして費用・運用設計が必要 |
実務ではどう選ぶか

AI駆動開発でRAGを作るなら、見るべきなのは「どちらが楽か」ではなく、エンジニア負荷がどこに残るかである。
AI駆動開発によって、RAG構築は3年前より大きく楽になりました。PoCコード、データ取り込み、Retriever設計、評価セット、ログ分析、運用ドキュメントは、AIと対話しながら高速に作れます。
しかし、エンジニアの負荷が消えたわけではありません。負荷の場所が変わっただけです。
Vertex AI / Agent Searchでは、検索基盤やインフラ運用の負荷は下がりますが、Google Cloud上でのIAM、データ接続、サービス制約、ログ、評価、コスト管理を理解する必要があります。
LlamaIndexでは、実装や実験の自由度は高い一方で、Retriever設計、評価、監視、障害時の切り分け、本番運用の責任を自社で持つ場面が増えます。
RAGプラットフォーム選定で見るべきなのは、「楽か大変か」ではなく、どの負荷をクラウドに移し、どの負荷をエンジニアリングとして残すかです。
エンジニア負荷の実態(AI駆動開発が前提の場合)

| 工程 | Vertex AI / Agent Search | LlamaIndex / LlamaCloud | AI駆動開発で効くこと |
|---|---|---|---|
| 初期構築 | マネージド機能により軽くしやすい | 自由度は高いが設計判断が多い | 構成案、サンプルコード、IaCのたたき台生成 |
| 文書取り込み | コネクタや設定ベースで扱いやすい | LlamaParse / LlamaCloudで複雑文書に対応しやすい | 前処理スクリプト、抽出確認、メタデータ設計案 |
| 検索品質改善 | サービス仕様の範囲で調整する | Retriever、Reranker、Chunkingを細かく制御できる | 比較実験、評価クエリ生成、失敗回答の分類 |
| 権限・監査 | Google CloudのIAMや監査基盤と組み合わせやすい | アプリ側・DB側で設計する責任が大きい | 権限マトリクス、監査ログ項目、テストケース作成 |
| 障害対応 | 基盤部分は任せられるが、サービス仕様の理解が必要 | 内部処理を追いやすいが、自社で見る範囲が広い | ログ要約、原因仮説、再現手順、改善チケット生成 |
| 継続運用 | 運用負荷は低めだが、クラウド依存は強い | 自由度は高いが、監視・評価・更新運用が重い | 運用Runbook、評価レポート、変更影響分析 |
つまり、AI駆動開発でRAGを作るエンジニアにとって重要なのは、コードを速く書けるかだけではありません。「なぜ検索されないのか」「なぜ答えが変わったのか」「誰に見えてよい情報なのか」を説明できる構成にすることです。
3つのアーキテクチャパターン
この負荷の置き場所を3つのアーキテクチャパターンに整理すると、選択肢はより具体的に見えてきます。全部をマネージドに寄せるのか、自由度を優先して自社で持つのか、あるいは文書処理・検索・アプリ制御を分けるのかで、設計は変わります。
| 構成 | 概要 | 向いているケース | 注意点 |
|---|---|---|---|
| マネージドRAG型 | Vertex AI RAG EngineやAgent Searchに寄せる | 短期導入、Google Cloud中心、運用負荷を下げたい | 細かな検索制御はサービス仕様に依存する |
| OSS設計型 | LlamaIndexでRAGパイプラインを自社設計する | 高度な検索、特殊ドメイン、研究開発、マルチクラウド | 設計・監視・セキュリティ・運用責任が重い |
| ハイブリッド型 | 文書処理はLlamaParse、検索運用はVertex AI、自社アプリで制御する | 本番品質と柔軟性を両立したい | 責任境界とコスト構造を明確にする必要がある |
特に大企業では、ハイブリッド型が現実的です。すべてをマネージドに寄せると柔軟性が足りず、すべてを自作すると運用が重くなるからです。RAGは「作れるか」ではなく、「守りながら改善し続けられるか」が本番導入の分かれ目です。
よくある失敗:「二択」で考えてしまう

RAGプラットフォーム選定の失敗は、ツール名だけで判断し、運用責任を見落とすことから始まる。
RAG基盤選定で最も多い失敗は、Vertex AIかLlamaIndexかという二択で考えてしまうことです。
ある企業では、LlamaIndexでPoCを完成させた後、本番化の段階で「部署ごとのアクセス権限をどうするか」という問いに詰まり、設計を見直すことになりました。別の企業では、マネージドサービスで本番稼働させたものの、「なぜこの文書が検索されないのか」をデバッグする手段が限られ、改善が止まりました。
どちらも、プラットフォームそのものの問題ではありません。選ぶ前に「自社は何を制御し、何をブラックボックスとして受け入れるのか」を決めていなかったことが原因でした。
| 失敗パターン | 何が起きるか | 回避策 |
|---|---|---|
| ツール名だけで選ぶ | 自社要件に合わない構成を採用する | クラウド、運用体制、文書品質、権限要件から逆算する |
| PoCコードをそのまま本番化する | 監視、評価、権限、差分更新で詰まる | PoC段階から本番運用項目をチェックする |
| 文書処理を軽視する | 検索以前にPDFや表の抽出で壊れる | RAGデータパイプラインを先に評価する |
| コストをLLM料金だけで見る | Embedding、検索、ストレージ、再処理、監視コストを見落とす | 初回投入・月次更新・検索回数・評価運用を含めて試算する |
| セキュリティを後付けする | 部署別権限や監査ログが設計し直しになる | access_role、IAM、監査、データ分離を初期設計に入れる |
| 将来のAgentic RAGを考えない | 再検索、自己評価、人間承認への拡張が難しくなる | ワークフロー化や評価基盤を見越して選定する |
プラットフォーム選定は、製品比較表を埋める作業ではありません。数ヶ月後、自社のRAGが本番で動き続けている姿を想像し、そのとき誰が、どのログを見て、どのデータを更新し、どの責任を負うのかを考える作業です。
2026年以降のRAG基盤戦略

2026年以降のRAG基盤は、検索システムからエージェント基盤の一部へ広がっていく。
RAGは、単なる検索QAから、業務エージェントの記憶・知識・根拠を支える基盤へ進化しています。Gemini Enterprise Agent Platformのように、RAG、メモリ、ワークフロー、評価、監査を含むエージェント基盤が整備されてきたことで、この流れは一層加速しています。
Google Cloud側では、Gemini Enterprise Agent Platformが、Agent Runtime、セッション、Memory Bank、評価、監視、トレース、IAM、Agent Gatewayなどを含む企業向けエージェント基盤として整理されています。
この流れの中で、RAGプラットフォームは「質問に答えるための検索基盤」だけではなく、「エージェントが参照し、判断し、行動するための根拠基盤」になります。つまり、今選ぶRAG基盤は、将来のAIエージェント基盤に直結します。
LlamaIndex側も同様に、単なるRAGライブラリから、ワークフロー、文書処理、エージェント、LlamaCloudへと広がっています。今後は、RAG基盤、文書AI、AIエージェント、Observability、Evalsが一体化していくと考えるのが自然です。
2026年版の見方:
3年後、あなたの会社のRAGはどうなっているでしょうか。
現場メンバーが「このRAG、なぜ答えが変わったのか分からない」と困っているのか、それとも「ログを見れば分かります」と説明できているのか。
その差は、今日どのRAG基盤を選ぶかで決まります。短期のPoC速度だけでなく、評価、監査、権限、ワークフロー、将来拡張まで含めて判断することが、単なる「ツール選定」と「経営判断」を分ける一線です。
まとめ
RAGプラットフォーム選びは、ツール比較ではなく、自社の運用責任と制御範囲を決める設計である。
Vertex AIとLlamaIndexは、単純な競合関係ではありません。
Vertex AI RAG Engine、Vertex AI Search、Agent Searchは、Google Cloud上でRAGを早く安全に構築・運用したい企業に向きます。
一方、LlamaIndexは、検索設計やワークフローを細かく制御したい開発チームに向きます。LlamaCloud / LlamaParseは、複雑な文書処理やIndexingをマネージド化したい場合に有力です。
大切なのは、「どれが一番優れているか」ではありません。自社のクラウド方針、開発体制、文書の複雑さ、セキュリティ要件、運用責任、将来のAgentic RAG構想から逆算することです。
ここで一度、手を止めて考えてみてください。あなたのRAGが1年後に本番で動いているとして、そのとき「なぜこの文書が検索されたのか」を説明できますか。
「なぜ昨日と答えが違うのか」をログから追えますか。「このユーザーにこの文書を見せてよいのか」をテストできますか。
その答えが見えていれば、どのプラットフォームを選ぶべきかが自然に見えてきます。
冒頭の企業の話に戻りましょう。
エンジニアが望む「柔軟性」、情シスが求める「マネージド運用」、経営の「半年後の全社展開」、法務の「権限と監査」。この四者の要件を同時に満たす唯一の答えはありません。どこに線を引くかを、誰と、いつ決めるのか――その設計こそがRAG基盤選定の本質です。
RAG基盤選定とは、AIに何を任せるかの前に、自社が何を持ち続けるかを決める作業です。
📋 RAGプラットフォーム選定チェックリスト
- 自社の標準クラウドはGoogle Cloudか、マルチクラウドかを確認する。
- RAGの目的が社内検索なのか、業務アプリなのか、AIエージェント基盤なのかを明確にする。
- 文書が単純テキスト中心か、PDF・表・帳票・画像中心かを棚卸しする。
- チャンク、Embedding、Vector DB、検索、再ランキングをどこまで自社で制御したいか決める。
- 権限制御、監査ログ、評価、差分更新を誰が運用するか決める。
- PoC基盤を本番化する前に、コスト、スケール、セキュリティ、評価運用を再確認する。
この記事を読んだエンジニアが、明日やること
- 「Vertex AIかLlamaIndexか」という問いを、「どの負荷をクラウドに逃がし、どの負荷を自社で持つか」に言い換える。
- PoCコードを作る前に、検索品質、権限、監査、ログ、再現性の責任範囲を決める。
- Google Cloud中心・短期本番化なら、Vertex AI RAG Engine / Agent Searchで下がる負荷と残る負荷を分けて確認する。
- 検索設計・ワークフロー・デバッグ可能性を重視するなら、LlamaIndexでどこまで自社制御するかを決める。
- 複雑なPDFや帳票が多いなら、RAG本体より先にLlamaParse / LlamaCloudの抽出品質を評価する。
専門用語まとめ
- RAGプラットフォーム
- RAGのデータ取り込み、検索、Embedding、生成、評価、運用を支える基盤。マネージドサービス、OSSフレームワーク、Vector DBなどを含む。
- Vertex AI RAG Engine
- Google Cloud上でRAG corpus作成、ファイル取り込み、チャンク化、Embedding、検索、Gemini連携を扱うためのマネージドRAG基盤。
- Vector Search 2.0
- Gemini Enterprise Agent Platformで利用されるフルマネージドなベクトル検索基盤。RAG Engine Serverless modeでは、RagManagedVertexVectorSearchとして利用される。
- Agent Search
- Gemini Enterprise Agent Platform上で、企業データを検索・生成AIアプリケーションにグラウンディングするための検索基盤。
- Gemini Enterprise Agent Platform
- Google Cloudが提供する企業向けエージェント基盤。エージェント実行、メモリ、評価、監視、IAM、検索・グラウンディングなどを含む。
- LlamaIndex
- RAGやLLMアプリケーションを構築するためのオープンソースフレームワーク。LlamaCloud / LlamaParseと組み合わせることで、文書AI基盤としての活用も広がっている。
- LlamaCloud
- LlamaIndex系のマネージドサービス。文書解析、抽出、インデックス作成、検索などを本番品質で扱うための基盤。
- LlamaParse
- 複雑なPDF、表、画像、手書きなどをAIアプリケーション向けのデータへ変換する文書解析基盤。
参考文献 / 出典
一次情報 / 公式ドキュメント
- Google Cloud Documentation – Vertex AI RAG Engine Quickstart
- Google Cloud Blog – Introducing Vertex AI RAG Engine
- Google Cloud Documentation – Vertex AI RAG Engine Serverless mode
- Google Cloud Documentation – Use Vector Search 2.0 with RAG
- Google Cloud Documentation – Grounding overview
- Google Cloud Documentation – Grounding with Vertex AI Search
- Google Cloud – Gemini Enterprise Agent Platform
- Google Cloud – Agent Search on Gemini Enterprise Agent Platform
- Google Cloud Documentation – Gemini Enterprise Agent Platform overview
- LlamaIndex Documentation – Welcome to LlamaIndex
- LlamaParse Platform Documentation – Quickstart
- LlamaParse Platform Documentation – Product overview
- LlamaIndex Blog – Introducing LlamaParse v2
- GitHub – LlamaIndex OSS repository
- LlamaIndex – LlamaCloud / LlamaParse
- LlamaIndex – LlamaParse Pricing and OSS FAQ
次に読むならこの3本
補足Q&A
Q1.
Vertex AIとLlamaIndexはどちらを選ぶべきですか?
A1.
Google Cloud上で早く安全に本番化したいならVertex AI系、検索設計を細かく制御したいならLlamaIndex系が向いています。
ただし二択で考える必要はありません。文書処理はLlamaParse、検索運用はVertex AI、自社アプリで制御するなど、役割を分ける構成も現実的です。どちらが「勝ち」かではなく、どこまでをクラウドに任せ、どこから先を自社の責任範囲として設計するかが本質です。
Q2.
Vertex AI RAG EngineとVertex AI Searchは何が違いますか?
A2.
RAG Engineは構成可能なRAG基盤、Vertex AI Searchは企業データやWebサイトを検索・グラウンディングする検索基盤として捉えると分かりやすいです。
実際の選定では、どのデータを、どの検索体験で、どのモデルに接続するかを基準に整理します。
Q3.
LlamaCloudやLlamaParseはLlamaIndexと同じものですか?
A3.
同じではありません。LlamaIndexはOSSフレームワーク、LlamaCloud / LlamaParseは文書処理やIndexingを支えるマネージドサービスとして捉えるのが自然です。
複雑なPDFや帳票を扱うRAGでは、LlamaParseのような文書解析基盤が検索品質に大きく影響します。
Q4.
PoCではLlamaIndex、本番ではVertex AIという使い分けは可能ですか?
A4.
可能です。ただし、PoC時点で本番の権限管理、差分更新、評価、監査ログを見越して設計しておく必要があります。
PoCコードをそのまま本番化すると、運用設計の不足で手戻りが発生しやすくなります。
Q5.
RAGプラットフォーム選びで最初に確認すべきことは何ですか?
A5.
最初に確認すべきなのは、標準クラウド、文書の複雑さ、運用体制、セキュリティ要件です。
ツールの機能表から入るより、自社がどこまで作り、どこからマネージドサービスに任せるかを決める方が、失敗しにくくなります。
更新履歴
- 2026年5月22日:v11.3に適合し、Vertex AI vs LlamaIndex比較記事を、RAGプラットフォーム選定ガイドとして全面再構成。Vertex AI RAG Engine Serverless mode、Vector Search 2.0、Agent Search、Gemini Enterprise Agent Platform、LlamaIndex、LlamaCloud、LlamaParse v2の情報を反映。AI駆動開発を行うエンジニア向けに、エンジニア負荷、デバッグ可能性、権限・監査、再現性、責任境界の観点を強化。
- 2025年4月:初版公開。Vertex AI RAG EngineとLlamaIndexの比較記事として構成。








